



[IJasia18] 전쟁의 한복판, 당신이라면 무엇을 기록하겠습니까?
2018년 10월 15일 13시 20분

2018년 10월 16일 11시 32분
데이터저널리즘에 입문하는 분들이 가장 많이 하는 질문은 무엇일까요? 바로 “코딩을 할 줄 몰라도 가능할까요?”입니다. 코드를 직접 작성할 수 있다면 더할나위 없이 좋겠지만 입문자에게 코드는 그저 까만 배경에 흰 알파벳 글씨일 뿐일지도요.
어렵고 복잡하게만 보이는 데이터저널리즘이지만, 구글 퓨전테이블, 인포그램, 태블로 등의 툴을 사용해 튜토리얼만 익힌다면 누구나 간단한 시각화 결과물을 제작할 수 있습니다. 한 번만 튜토리얼을 따라 해보면 직관적으로 이것저것 만져보며 익힐 수 있는 툴이 참 많습니다.
사실 데이터저널리즘의 첫 고비는 분석, 시각화가 아닌 수집 단계에서 마주하게 되는데요. 쓸만한 데이터를 분석 가능한 형태로 얻을 수 있다면 좋겠지만, 내 입맛에 맞게끔 가공해 데이터를 안겨주는 경우는 없습니다. 예를 들어 정부 기관에 정보공개청구를 해보셨다면 hwp, pdf 확장자 파일을 받을 확률이 가장 높습니다. 또는 어느 페이지에 공개돼 있으니 직접 긁어서 사용하라고 안내하는 경우도 꽤 많습니다.
원하는 데이터가 웹페이지에 공개되어있을 때, 코드를 작성할 수 없는 당신은 어떻게 하실 건가요? 같은 고민을 가진 아시아 기자들이 답을 얻기 위해 “Web-Scraping(웹페이지 긁기)” 세션에 모였습니다. 터키 이스탄불에서 데이터저널리즘을 가르치는 Pinar Dag 교수와 말레이시아에서 데이터저널리즘을 교육하는 Kuek Ser Kuang Keng 컨설턴트가 공유한 팁을 전해드릴까요?

국가별 아시안게임 메달 획득 현황을 긁어야 합니다. 여러분은 어떤 방법을 사용하실 건가요? 혹시 드래그-복사(Ctrl + C)-붙여넣기(Ctrl + V)를 생각하셨을까요? 아시안게임 기간 중이라 순위가 계속 바뀌고 실시간으로 업데이트된다면 어떻게 해야 할까요? 계속 복사-붙여넣기를 할 수는 없을 노릇입니다. 이럴 때 구글 스프레드시트만 있다면 강력한 함수 한 줄로 문제는 해결 가능합니다. 바로 IMPORTHTML입니다.
IMPORT함수는 웹페이지 형태에 따라 IMPORTHTML, IMPORTXML로 구분해 사용가능합니다. 우선 1단계, 구글 스프레드시트를 엽니다. 2단계, 첫번째 셀에 “=IMPORTHTML(“URL”, “table”, N)을 입력하면 끝입니다. URL은 긁고 싶은 페이지의 링크, table은 표, N은 색인으로 예시에서는 몇 번째 표를 불러올 것인지를 의미하는데요. 예시로 올림픽 메달 순위를 긁어볼까요? 첫 번째 셀에 “=IMPORTHTML(“https://en.asiangames2018.id/medals/”,”table”,0)”로 입력하자 다음과 같이 데이터를 불러왔네요. 함수를 새로고침하면 웹페이지에 업데이트된 내용이 자동으로 반영됩니다.

IMPORTHTML 함수로도 가져오지 못하는 데이터는 많습니다. 다른 예시로 ‘전 세계 대학 순위'를 살펴볼까요? 해당 페이지는 HTML구조로 이뤄지지않아 IMPORTHTML로 데이터를 불러올 수 없습니다. 그렇다면 페이지가 어떻게 생겼는지 살펴봐야겠습니다. 웹페이지에서 우클릭을 사용해 ‘검사(Inspect) - 네트워크(Network)’를 누른 뒤 페이지를 새로고침하자 다음 화면이 뜹니다.

IMG 탭을 눌러보면 로고를 비롯해 웹페이지에 사용된 이미지 파일을 확인할 수 있습니다. 데이터는 어디 있을까요? XHR 탭을 확인하면 JSON 파일들을 확인할 수 있습니다. JSON은 데이터를 저장하는데 굉장히 유용한 형식입니다. JSON 파일을 더블클릭하면 데이터를 열어 확인할 수 있습니다. 그중 World University Ranking JSON 파일을 열면 우리가 원하던 ‘전 세계 대학 순위’ 정보가 담겨있습니다.

JSON 파일을 사용하기 어려운 분이라면 구글에 ‘JSON convert to CSV’를 검색해 보세요. 자동으로 변환해주는 무료 사이트를 찾을 수 있습니다. 또는 위 내용을 복사해 TXT 파일로 저장한 뒤 엑셀에서 열어 ‘구분기호로 텍스트 열 나눔' 등의 기능을 사용해 정제할 수도 있습니다.
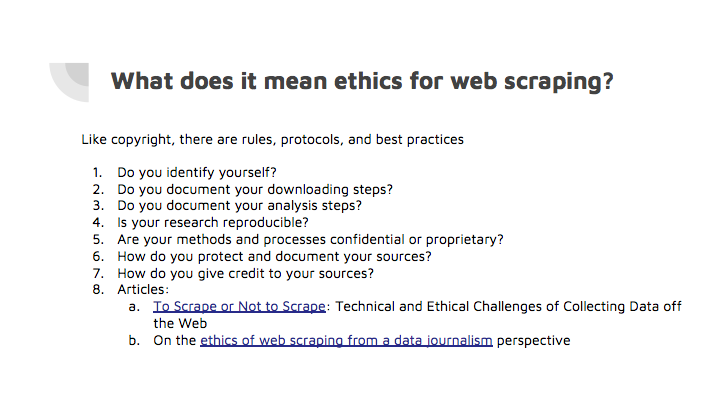
개인은 연구, 저널리즘 등 저마다의 이유로 데이터를 분석하고 시각화하고자 웹페이지를 긁습니다. 하지만 표절, 스팸, 사칭 등 악용 사례도 많습니다. 불법적인 웹스크랩 대행 서비스로 수익을 올리는 업체들도 성행합니다. 때문에 웹페이지를 긁고자 하는 모든 이가 지켜야 하는 윤리 원칙들이 있는데요. 세션에서는 단순히 웹페이지를 긁는 기술만이 아니라 더 나은 사회를 위해 함께 지켜야 할 원칙들도 공유하는 시간을 가졌습니다. 발표자 Pinar Dag 교수는 “스크랩봇이 웹사이트가 규정한 모든 규칙을 지키고 스크랩된 데이터가 좋은 의도로 사용되는 한 데이터 스크래핑은 윤리적 행위"라며 세션을 마무리했습니다.
이날 세션에서는 이밖에도 저널리스트를 위한 온라인 도구로 PDF에서 표 데이터를 추출하는 Tabula, 데이터를 정제하는데 사용하는 Openrefine 등이 소개됐습니다.
정리 : 뉴스타파 연다혜
뉴스타파는 권력과 자본의 간섭을 받지 않고 진실만을 보도하기 위해, 광고나 협찬 없이 오직 후원회원들의 회비로만 제작됩니다. 월 1만원 후원으로 더 나은 세상을 만들어주세요.
2018년 10월 15일 13시 20분

2018년 10월 12일 10시 18분

2018년 10월 11일 09시 54분

2018년 10월 08일 14시 34분